前回の実験の後、前回使用していた計測ツールで、ネットワークの問題で1秒あたり500個のジョブしか処理ができない問題が発覚しました。
今回は上記の問題を避けるため、Rustで実装した計測ツールを使用し、再検証を行いました。
目的
- 「TCPを介した分散処理でTIME_WAITにハマった話」にて、今まで使用していた計測ツールでネットワークの問題が判明し、処理速度の上限が決まってしまっていたため、ツールを変更して前回の実験の再検証を行う。
準備
今回の実験にて、下記のものを用意しました。
- k8sクラスタ
- 前回の実験と同様の構成のものを使用しています。
- MacBook Air (M1, 2020)
- CPU: Apple M1 8コア
- RAM: 16 GB
- 計測アプリ
- https://github.com/mochi256/performance_tester
- commit: 23c793479808ebb1b2eebf8cfdaeb1e26b269b11
方法と結果と考察
0. 計測アプリについて
「準備」の項に記載した計測アプリですが、下記の仕様となっています。
アプリの仕様
前回の「アプリの仕様」の項と同じ仕様のうえ、ジョブを任意の数でクライアントへ渡せるようになっています。
計測区間について
前回の「計測区間について」の項と同じ方式のため、説明を省きます。
1. 最適な並列実行数の検証
実験方法
前回の「1. 最適な並列実行数の検証」の項と、下記に述べる部分以外同じ方法のため、説明を省きます。
今回の素数判定を行う値は1〜1,000,000までとし、クライアントへ渡すジョブの数は10,000毎になっています。
また今回は比較対象として、M1チップ搭載のMacBook Airと、1ノードのみで処理させたk8sクラスタの平均処理速度を同時に計測しました。
実験結果
結果として、各端末の平均処理速度は、以下のようになりました。
| 並列数(個) | k8s 1ノード | k8s 4ノード | MacBook Air |
|---|---|---|---|
| 1 | 163.765 | 166.126 | 27.221 |
| 2 | 82.573 | 84.110 | 14.390 |
| 3 | 59.774 | 55.132 | 10.361 |
| 4 | 58.974 | 41.977 | 8.281 |
| 5 | 58.864 | 34.337 | 8.417 |
| 6 | 59.514 | 29.693 | 9.013 |
| 7 | 59.348 | 26.202 | 9.066 |
| 8 | 59.134 | 23.092 | 9.110 |
| 9 | 60.131 | 23.007 | 8.729 |
| 10 | 59.704 | 22.131 | 8.409 |
| 11 | 59.781 | 19.816 | 8.195 |
| 12 | 59.613 | 19.778 | 8.059 |
結果を図示すると、以下のようになります。
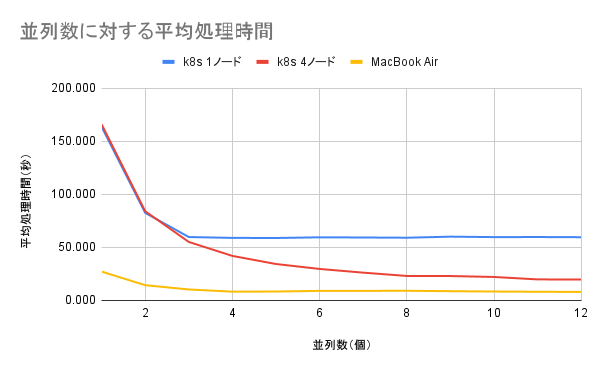
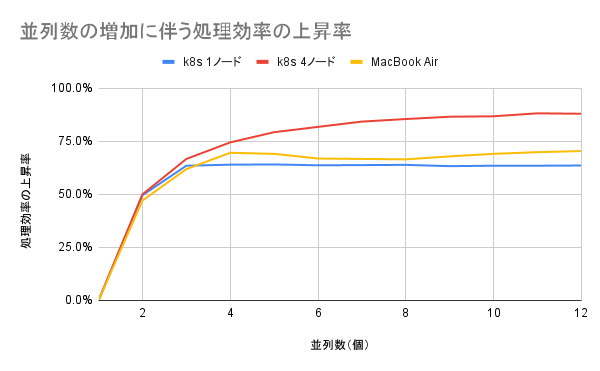
また、各端末の1並列のパフォーマンスに対し、並列数を増加させることで、どれ程処理速度が向上したかは、下記のようになりました。
| 並列数(個) | k8s 1ノード | k8s 4ノード | MacBook Air |
|---|---|---|---|
| 1 | 0.0% | 0.0% | 0.0% |
| 2 | 49.6% | 50.0% | 47.1% |
| 3 | 63.5% | 66.7% | 61.9% |
| 4 | 64.0% | 74.5% | 69.6% |
| 5 | 64.1% | 79.3% | 69.1% |
| 6 | 63.7% | 81.8% | 66.9% |
| 7 | 63.8% | 84.3% | 66.7% |
| 8 | 63.9% | 85.5% | 66.5% |
| 9 | 63.3% | 86.6% | 67.9% |
| 10 | 63.5% | 86.8% | 69.1% |
| 11 | 63.5% | 88.2% | 69.9% |
| 12 | 63.6% | 88.0% | 70.4% |
結果を図示すると、以下のようになります。
考察
- 計測に使うアプリを改修しk8sクラスタの再検証をしたところ、前回の結果で5並列がベストであったところが、12並列が最も処理速度が速いことがわかった。
- これは、秒間あたりにサーバ-クライアント間で送受信できるジョブの数が増えたことによると思われる。
- また、k8sの1ノードでは8並列、Macでは4並列が最も効率が良いことがわかった。
- 両方とも実質1端末での実行であるが、Macの方はCPUの性能が圧倒的に良いため、並列処理による効率化可能な部分を効率化してしまい、並列数が少なくなっているものだと思われる。
2. 同じ並列数・異なるノード数による処理時間の変動の検証
実験方法
前回の「2. 同じ並列数・異なるノード数による処理時間の変動の検証」の項と、下記に述べる部分以外同じ方法のため、説明を省きます。
今回の素数判定を行う値は1〜1,000,000までとし、クライアントへ渡すジョブの数は10,000毎になっています。
また、前回の並列数は4でしたが、今回は4ワーカーノードのk8sクラスタで最も効率の良かった12で固定しています。
実験結果
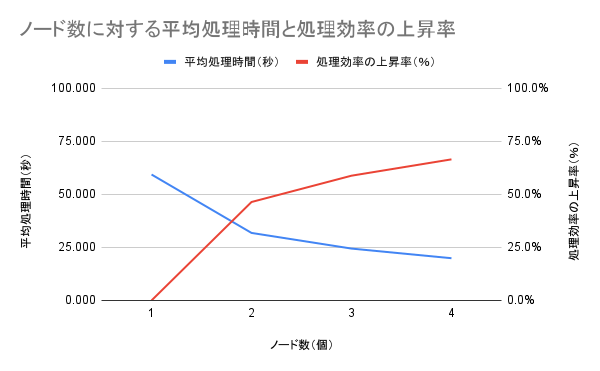
結果として、k8sクラスタで使用できるノード数を制限して12並列で処理を行った際の、平均処理時間と処理効率の上昇率は、下記のようになりました。
| ノード数(個) | 計測1回目(秒) | 計測2回目(秒) | 計測3回目(秒) | 平均処理時間(秒) | 処理効率の上昇率(%) |
|---|---|---|---|---|---|
| 1 | 59.839 | 59.406 | 58.818 | 59.354 | 0.0% |
| 2 | 31.024 | 31.714 | 32.739 | 31.826 | 46.4% |
| 3 | 23.866 | 24.719 | 24.770 | 24.452 | 58.8% |
| 4 | 20.267 | 19.778 | 19.683 | 19.909 | 66.5% |
結果を図示すると、以下のようになります。
考察
- 前回は2ノード以上でパフォーマンスが頭打ちになってしまっていたが、計測ツールを変えることでノード数に比例して処理効率が上昇するようになった。
- 今回は4ノード以上用意していないため、それ以上のパフォーマンスの向上率が確認できないが、「1. 最適な並列実行数の検証」でk8s 1ノード、Macの処理の上昇率が60%後半あたりになっていることから、k8sによるジョブの並列処理も4〜5ノードが処理のピークになっていると思われる。
おわりに
今回の実験では、パフォーマンス測定ツールを改修することにより、前回の実験よりも精度の高い結果を得られました。
結果として、k8sクラスタのジョブの並列処理を行う場合、ワーカーノードを4〜5個用意するのが、最もパフォーマンスを得られると思われます。
今回は以上になります。
ここまで読んでいただき、ありがとうございました!