■ 2022-04-10 追記
本記事の実験「1. k8sクラスタのジョブ実行で最適な並列数の測定」ですが、実験方法に不備があったため、結果に誤りがあります。
詳細は「k8sクラスタによる並列処理のパフォーマンス検証【2】」をご確認ください。
以前RaspberryPiで構築したk8sクラスタですが、k8sはアプリのデプロイを行う際に複数のPodを起動し、冗長化を行うことができるなど、ITインフラとして様々な用途で使用することができます。
その中で、自分は「ジョブの実行」ができる点に興味を持ちました。
クラスタリングを行った計算機で並列処理や分散処理を行う場合、処理の対象となるデータの計算量に対し、構成する端末を増やすことで、処理速度を速めることができます。
今回はk8sを計算機クラスタとして使ううえで、色々実験を行ってみました。
目的
今回の実験の目的は、下記のものになります。
- 前回構築した環境(1マスターノード、2ワーカーノード)でジョブの並列実行を行う場合、何並列(何Pod)で実行するのが最適か確認する。
- またk8sの構築にかかった費用と、同じ価格帯のPC(mouse C1)の処理速度を比べた場合、どちらが速く処理を行えるか。
準備
今回の実験にて、下記のものを用意しました。
- mouse C1
- OS: Windows10
- プロセッサ: Intel(R) Celeron(R) N4100 CPU @ 1.10GHz 1.10 GHz
- RAM: 8.00 GB
- k8sクラスタ
- 計測アプリ
- https://github.com/mochi256/throughput_measurement_tools
- commit: 5956e2f166d9a62d64860f80e49b0b5831ca3e5d
方法と結果と考察
0. 計測アプリについて
「準備」の項に記載した計測アプリですが、下記の仕様となっています。
アプリの仕様
- アプリはサーバとクライアントに分かれています。
- サーバは起動時にカウントの最大値を引数(APP_COUNT_MAX)で取り、サーバにアクセスされる毎に1から順にカウントを行い、引数の値までの数値をクライアントへ返します。
- サーバのカウントが引数の値を超えた場合、nullが返るようになります。
- クライアントは起動時に接続先のURLを引数(APP_URL)を取り、対象のURLへアクセスを行い、取得した数値の素数判定を行います。
- クライアントの素数判定の処理は、サーバからnullが返ってくるまで、逐次実行され続け、nullが返ってきた場合はプログラムを終了します。
計測区間について
- 処理速度の計測区間は、クライアント実行時の「client_start」というログの出力時から、クライアント終了時の「client_terminated」というログが出力されるまでとします。
- クライアントの並列実行を行う場合は、最初に起動されたクライアントの「client_start」というログから、最後に実行されていたクライアントの「client_terminated」というログが出力されるまでとします。
1. k8sクラスタのジョブ実行で最適な並列数の測定
実験方法
まずは、構築したk8sクラスタでジョブの並列実行を行う場合、何並列が最もパフォーマンスが出るかの確認になります。
下記の手順で実験をしました。
- APP_COUNT_MAXを10000に設定し、app-server.ymlをデプロイする。
- 並列数(completions, parallelism)を任意の値に設定し、app-job.ymlをデプロイする。
- "kubectl get pods"コマンドで、ジョブのコンテナが全て完了することを確認する。
- "kubectl logs {{ ジョブのコンテナ名 }}"を実行し、クライアントのログを取得する。
- 最初にクライアントが実行された時間から、最後にクライアントが実行された時間を記録する。
- サーバ、ジョブのコンテナを全て終了する。
- 並列数を1~5として、手順1~6までを繰り返す。
実験結果
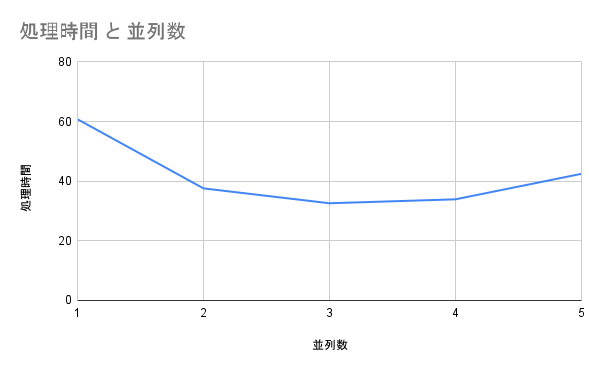
結果として、以下のようになりました。
| 並列数(個) | 処理時間(秒) |
|---|---|
| 1 | 60.767 |
| 2 | 37.582 |
| 3 | 32.596 |
| 4 | 33.917 |
| 5 | 42.467 |
結果を図示すると、以下のようになります。
考察
- 1マスター・2ワーカーノードの構成の場合、3並列が最もパフォーマンスが良いことがわかった。
- 4~5並列の場合に処理時間が長くなっているが、今回の構成だと同時に起動できるPod(ジョブ)が3つまでとなっていた。
その3つPodが終了した後に残りのPodが起動され、処理時間が伸びていたことが原因であった。 - ワーカーノードをさらに増やすことで、処理時間を早められると思うが、もしかしたらカウントを行うサーバの効率化(キューを使うなど)も行う必要があると思われた。
2.処理速度の比較
実験方法
次に、処理速度の比較になります。
「1. k8sクラスタのジョブ実行で最適な並列数の測定」にて、今回用意したk8sの環境だと、3並列で実行することが最もパフォーマンスが良いことがわかりました。
そのため、今回は下記3つの方法で計測アプリを使用した場合、どのような処理速度の差が生じるかを確認します。
- マスターノード1、ワーカーノード2の構成と同価格帯の「mouse C1」にて、直列でアプリを実行する。
- k8sクラスタを構成しているRaspberryPiにて、直列でアプリを実行する。
- k8sクラスタにて、3並列でアプリを実行する。
上記3種類の方法で、素数判定の処理数(APP_COUNT_MAX)を1000~100000まで設定し、処理終了までに何秒かかるかを計測します。
実験結果
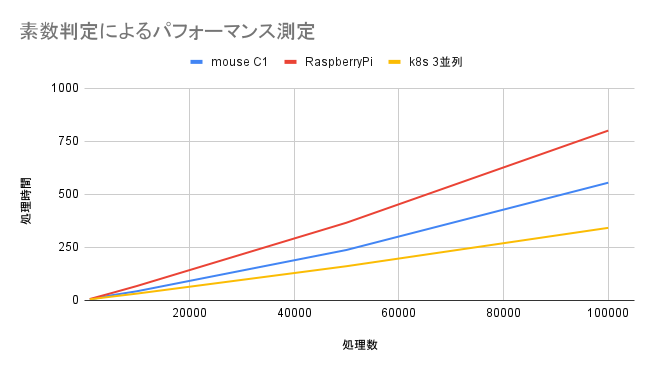
結果として、以下のようになりました。
| 処理数(個) | mouse C1(秒) | RaspberryPi(秒) | k8s 3並列(秒) |
|---|---|---|---|
| 1000 | 4.160 | 6.728 | 5.355 |
| 5000 | 23.702 | 33.597 | 17.533 |
| 10000 | 43.359 | 68.087 | 32.303 |
| 50000 | 237.820 | 366.337 | 161.320 |
| 100000 | 554.985 | 800.588 | 342.183 |
結果を図示すると、以下のようになります。
考察
- 3方式を比較し、最終的に最も処理が速かったものはk8sでの実行であった。
- 処理数が1000の場合、k8sは2番目に速いこととなっているが、これは恐らくPodの起動・終了に時間がかかっていると思われる。
- RaspberryPiで処理数10000に設定した場合の速度は、k8sクラスタの1並列で処理を行った際より、約8秒遅い結果となっていた
※「1. k8sクラスタのジョブ実行で最適な並列数の測定」の項を参照 - 処理数1000の時にRaspberryPiがk8sより遅くなる点と、上述の処理数10000のk8sの1並列の処理よりもRaspberryPiの処理が遅い点が、不可解であった。
(k8sで命令を通さない分速くなると思ったが、そうでもなかった。もしかしたら、OSインストール直後の端末で計算を行ったほうが、余計な処理が走っておらず、速くなったかもしれない)
おわりに
今回実験を行った結果、RaspberryPi 4Bの1マスターノード、2ワーカーノードの構成のk8s環境を作成した場合、ジョブは3並列が最もパフォーマンスが良く、同価格帯のmouse C1のノートパソコンよりも、1.5~6倍ほど速く処理が行えることがわかりました。
ただ、実験中に「5つ同時に起動するジョブのPodが、3つまでしか同時に起動しない」ということが起こっていました。
そこで「ワーカーノードの数に対し、同時起動できるジョブの数はいくつなのか(ノード数に対し、比例するのか)」という点が気になりました。
なので、今後ラズパイが追加で手に入りましたら、そこら辺の検証もするかもしれません。
今回は以上になります。
ここまで読んでいただき、ありがとうございました!
実験時のメモ
以下は今回の実験を行った際の、自分向けのメモになります。
Dockerイメージの登録
k8sで計測アプリを実行する際、DockerHubにイメージをpushし、k8sクラスタでpullすることとしました。
下記のコマンドで登録をしたのですが、当時dockerイメージはビルドした端末のアーキテクチャに依存することを知らず、Windows(amd64)でビルドしたイメージをk8sにデプロイしたところ、
「standard_init_linux.go:219: exec user process caused: exec format error」
というエラーが発生し、困ったりしました。
(使用するラズパイでイメージのビルド&pushを行ったことで、今回は解決しています。)
docker build -t throughput_measurement_tools .
docker tag throughput_measurement_tools mochi256/throughput_measurement_tools
docker push mochi256/throughput_measurement_tools