■ 2022-05-22 追記
本記事の実験で使用されている計測ツールにネットワークの問題で1秒あたり500個のジョブしか処理ができない問題があることがわかりました。
そのため、今回と同様の実験の再検証を「k8sクラスタによる並列処理のパフォーマンス検証【3】」にて行いました。
以前、Raspberry Piで構築したk8sを使用し、ジョブの並列実行のパフォーマンス検証を行いました。
今回は、さらに2個のRaspberry Pi(以下「ラズパイ」と呼称)を手に入れたので、その2個をワーカーノードに追加し、色々実験を行いました。
また、前回の検証時に「2ワーカーノード、3並列以上でジョブをデプロイした場合、全てのPodが同時に起動しない」という問題が発生していました。
今回判明したことなのですが、この原因はどうやらクラスタのリソースの問題ではなく「ジョブを動かすノードでイメージがPullされていなかった」ことが問題でした。
そのため、今回は全てのワーカーノードでイメージがPullされている状態で、コンテナ起動の待機時間が発生しないように実験を行いました。
目的
今回の実験の目的は、下記のものになります。
- 1マスターノード、4ワーカーノードのk8sクラスタでジョブの並列処理を行う場合、最適な並列実行数はいくつか
(2ワーカーノードの場合、3並列がベストであったが、4ワーカーノードの場合も同様なのか気になった) - 上記で求めた並列実行数を1~4ワーカーノードで実行する場合、処理がどの程度変動するか
(処理速度がワーカーノードに依存する場合、ワーカーノードが減るごとに処理時間が伸びるはず)
準備
今回の実験にて、下記のものを用意しました。
- k8sクラスタ
- 下記の記事で構築したk8sクラスタに、ラズパイ4 Model B(4GB)をワーカーノードに追加しています。
- https://mochi256.com/log/d04da823b34149b2b78addebdb414220
- 計測アプリ
- https://github.com/mochi256/throughput_measurement_tools
- commit: 5956e2f166d9a62d64860f80e49b0b5831ca3e5d
方法と結果と考察
0. 計測アプリについて
「準備」の項に記載した計測アプリですが、下記の仕様となっています。
アプリの仕様
前回の「アプリの仕様」の項と同じ仕様のため、説明を省きます。
計測区間について
処理速度の計測区間は、最初のクライアント実行時の「client_start」というログの出力時から、最後に素数の判定結果が出力される「[0-9]+_is(|_not)_prime」というログまでとします。
処理時間は、下記コマンドを実行してログから確認を行います。
kubectl get pods | grep -oP "indexed-job-\d+\S+"|xargs -I {} bash -c "kubectl logs {}"|sort|less
1. 最適な並列実行数の検証
実験方法
最初に、1マスターノード、4ワーカーノードの場合の最適な並列実行数の検証を行いました。
ワーカーノードが2機であった前回の実験では、3並列が最も効率が良いことがわかりました。
もし、ノードの数によって最適な並列数が変動するのであれば、3並列以上の場合の方が、処理速度が上がると考えたためです。
下記の手順で実験を行いました。
- APP_COUNT_MAXを50000に設定し、app-server.ymlをデプロイする
- 並列数(completions, parallelism)を任意の値に設定し、app-job.ymlをデプロイする
- "kubectl get pods"コマンドで、ジョブのコンテナが全て終了することを確認する
- "kubectl logs {{ ジョブのコンテナ名 }}"を実行し、クライアントのログを取得する
- 最初にクライアントが実行された時間から、最後にクライアントが実行された時間を記録する
- サーバ、ジョブのコンテナを全て終了する
- 同じ並列数を指定し、手順1~6を3回繰り返す
- 任意の並列数でそれぞれ3回データを取り、処理時間の平均値を求めたら、手順1~7までを繰り返す
実験結果
結果として、以下のようになりました。
| 並列数(個) | 計測1回目(秒) | 計測2回目(秒) | 計測3回目(秒) | 平均処理時間(秒) |
|---|---|---|---|---|
| 1 | 368.020 | 371.808 | 368.164 | 369.331 |
| 2 | 196.069 | 196.914 | 195.652 | 196.212 |
| 3 | 136.980 | 136.879 | 136.252 | 136.704 |
| 4 | 117.754 | 117.224 | 117.224 | 117.401 |
| 5 | 99.807 | 105.468 | 106.356 | 103.877 |
| 6 | 102.868 | 102.518 | 99.891 | 101.759 |
| 7 | 95.128 | 97.882 | 93.547 | 95.519 |
| 8 | 101.232 | 83.086 | 101.289 | 95.202 |
| 9 | 102.032 | 100.891 | 102.890 | 101.938 |
| 10 | 103.599 | 96.229 | 93.651 | 97.826 |
| 11 | 98.144 | 99.164 | 95.946 | 97.751 |
| 12 | 100.321 | 93.978 | 101.138 | 98.479 |
結果を図示すると、以下のようになります。
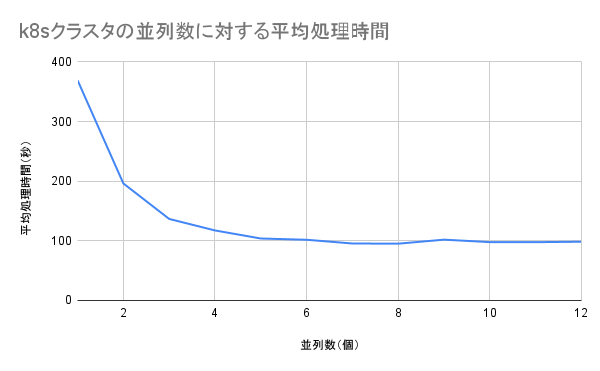
考察
- 1マスター・4ワーカーノードで最適な並列数を求めたところ、3並列ではなく、5並列が最も処理効率が良いように見えた
- 5並列以降、処理時間がほぼ100秒で推移していた
これは、アムダールの法則による処理効率の限界だと思われる
2. 同じ並列数・異なるノード数による処理時間の変動の検証
実験方法
今回の「1. 最適な並列実行数の検証」によって、5並列が最もパフォーマンスが良いことがわかりました。
これを「ワーカーノード4機の場合の、最も良い並列数である(並列処理のパフォーマンスがノード数に依存している)」と仮定するのであれば、ワーカーノードが4機未満の場合、そのパフォーマンスが下がることを期待し、実験を行います。
今回はジョブが実行されるワーカーノードを1~3に制限し、素数判定の処理数(APP_COUNT_MAX)を500000まで設定し、5並列のジョブによって、処理終了までに何秒かかるかを計測します。
実験結果
結果として、以下のようになりました。
| ノード数(個) | 計測1回目(秒) | 計測2回目(秒) | 計測3回目(秒) | 平均処理時間(秒) |
|---|---|---|---|---|
| 1 | 159.999 | 160.501 | 160.158 | 160.219 |
| 2 | 107.200 | 108.943 | 107.964 | 108.036 |
| 3 | 107.814 | 107.450 | 108.077 | 107.780 |
| 4 | 99.807 | 105.468 | 106.356 | 103.877 |
結果を図示すると、以下のようになります。
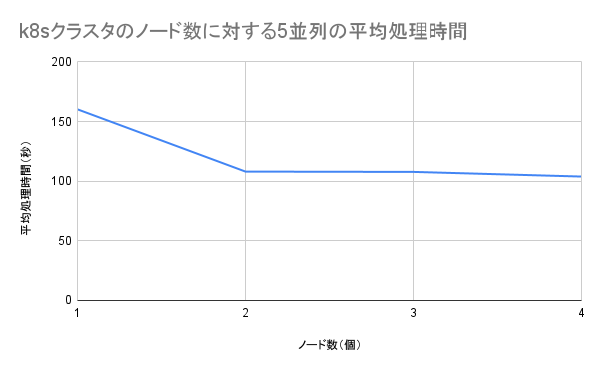
考察
- 意外であったが、ノード数が2個以上の場合、測定結果に大きな差が生じないことがわかった
- この実験結果からは「2個以上のラズパイのk8sクラスタでは、ノードを増やすことによる、ジョブの実行速度の上昇が見込めない」ということになる
-
また、前回の検証時「ワーカーノード2機の場合、3並列がベストである」という結論になったが、今回の結果によって否定されることになる
(前回の検証時には「5並列で処理を行おうとすると、同時に3並列までしかコンテナが起動しない」という問題が発生していたが、これは冒頭にも記載したように、恐らくノードでイメージがPullされていなかったことが原因) - もしかしたら、計測アプリの仕様によって今回の結果が発生した可能性がある
(サーバとジョブ実行のPodがHTTPによる通信を伴うため、ネットワーク内のパケットの配送が限界になっていたか、サーバの処理限界が100秒あたり50000アクセスまでであったか)
おわりに
今回の実験で、ワーカーノード4個の際に、最適な並列処理数を求めました。
しかし、実験結果ではワーカーノードが2個以上の場合、5並列でパフォーマンスがほぼ同一になってしまいました。
なので、次回に実験を行うとしたら、これがアムダールの法則の限界によるものなのか、実験ツールの方式によるものなのか、実験ツールや実験方法を変更して、原因を確かめてみようと思います。
今回は以上になります。
ここまで読んでいただき、ありがとうございました!